Résumé
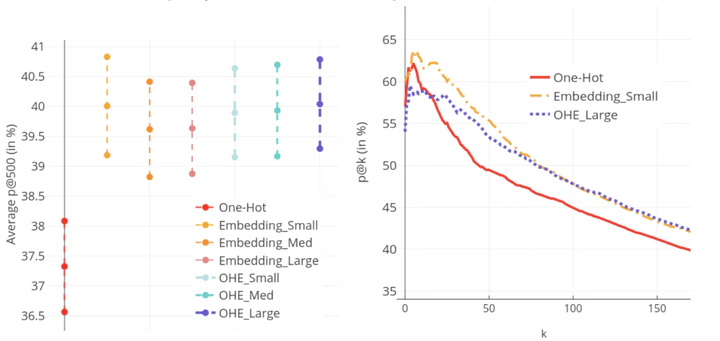
In this paper we propose a new generic method to work with categorical variables in case of sequential data. Our main contributions are - (1) The use of unsupervised methods to extract sequential information, (2) The generation of embeddings including this information for categorical variables using the well-known Word2Vec neural network. The use of embeddings not only reduced the memory usage but also improved the machine learning algorithms learning capacity from data compared with commonly used One-Hot encoding for example. We implemented those processes on a real world credit card fraud dataset, which represents more than 400 million transactions over a one year time window. We demonstrated that we were able to reduce the memory usage by 50% and to improve performance by 3% while using only a small subset of features.