A Technical Note on Non-Stationary Parametric Bandits: Existing Mistakes and Preliminary Solutions
Abstract
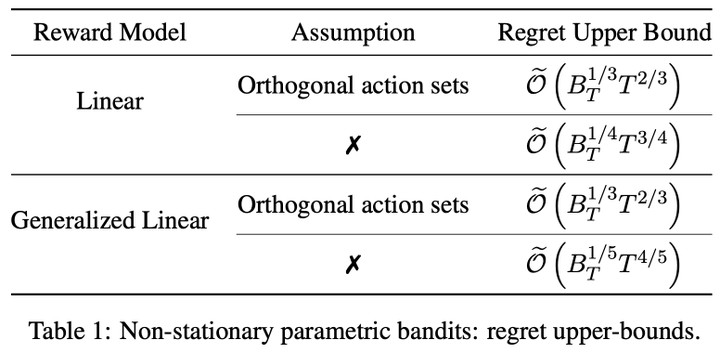
In this note we identify several mistakes appearing in the existing literature on non-stationary parametric bandits. More precisely, we study Generalized Linear Bandits (GLBs) in drifting environments, where the level of non-stationarity is characterized by a general metric known as the variation-budget. Existing methods to solve such problems typically involve forgetting mechanisms, which allow for a fine balance between the learning and tracking requirements of the problem. We uncover two significant mistakes in their theoretical analysis. The first arises when bounding the tracking error suffered by forgetting mechanisms. The second emerges when considering non-linear reward models, which requires extra care to balance the learning and tracking guarantees. We introduce a geometrical assumption on the arm set, sufficient to overcome the aforementioned technical gaps and recover minimax-optimality. We also share preliminary attempts at fixing those gaps under general configurations. Unfortunately, our solution yields degraded rates (w.r.t to the horizon), which raises new open questions regarding the optimality of forgetting mechanisms in non-stationary parametric bandits.